
使用bs4下载所有xkcd漫画
背景
我第一次知道python爬虫,是在我看到了这么一本书,书的名字是《Python编程快速上手:让繁琐工作自动化》(网上找图的时候,突然发现出第二版了,我找时间自己看看)。不过我不推荐大家去阅读这本书,因为这本书用的python版本是3.4,而我的python版本是3.12。就是因为版本相差太大,导致书上很多代码都无法实现。这本书的涉及面挺广的,介绍了很多有趣的第三方库。上面有一个项目,叫做“下载所有xkcd漫画”,为了实现这个项目,书上介绍了和爬虫密切相关的两个库:requests和bs4。接下来,我会来回顾这个项目。
两个第三方库requests和bs4
requests
requests是爬虫中最常用的一个第三方库。
我们先来安装requests,此处安装的版本是2.32.3
1 | > pip install requests |
安装完成之后就可以使用requests了。
1 | import requests |
通常导入的库和其他代码要用两行分隔。res,又叫response对象(也可以使用其他名字,res或response只是比较常用的叫法),有两种常用的属性text和content,text属性是以文本的形式,content是以字符的形式(回车、空格等都以转义字符的形式显示)。
bs4
使用pip安装bs4,我安装的版本是4.12.3。
1 | > pip install beautifulsoup4 |
使用bs4
1 | import requests |
soup,又叫beautifulsoup对象。soup对象有一个常用的方法叫做select(),可以用这个方法寻找我们需要的元素。
| 传递给select()的css selector | 匹配的对象 |
|---|---|
| soup.select(‘div’) | 所有名为< div>的元素 |
| ‘#author’ | id属性为author的元素 |
| ‘.notice’ | 所有class属性名为notice的元素 |
| ‘div span’ | 所有在< div>中的< span>元素 |
| ‘div > span’ | 所有直接在< div>之类的< span>元素,且中间无其他元素 |
| ‘input[name]’ | 所有名为< input>,并有一个name属性,name的值随意 |
| ‘input[type=“button”]’ | 所有名为< input>,并有一个type属性,其值为button |
上面的表格只是列举了几种常见的情况,在使用时可以直接在浏览器(我常用的是Google chrome)开发者模式elements内单击鼠标右键复制selector。
select()方法返回一个tag列表,常用elements表示。tag值,常用element表示,可以传递给str()函数,显示其代表的HTML标签。element也可以有attrs属性,它将该element的所有HTML属性作为一个字典。对element使用get_text()方法,可以获取元素的文本。对element使用get(‘属性名’)方法可以获取对应的属性值。
需要特别注意的是,bs4适用于静态网页,对于动态网页,bs4将失效。
下载所有xkcd漫画
分析xkcd网站
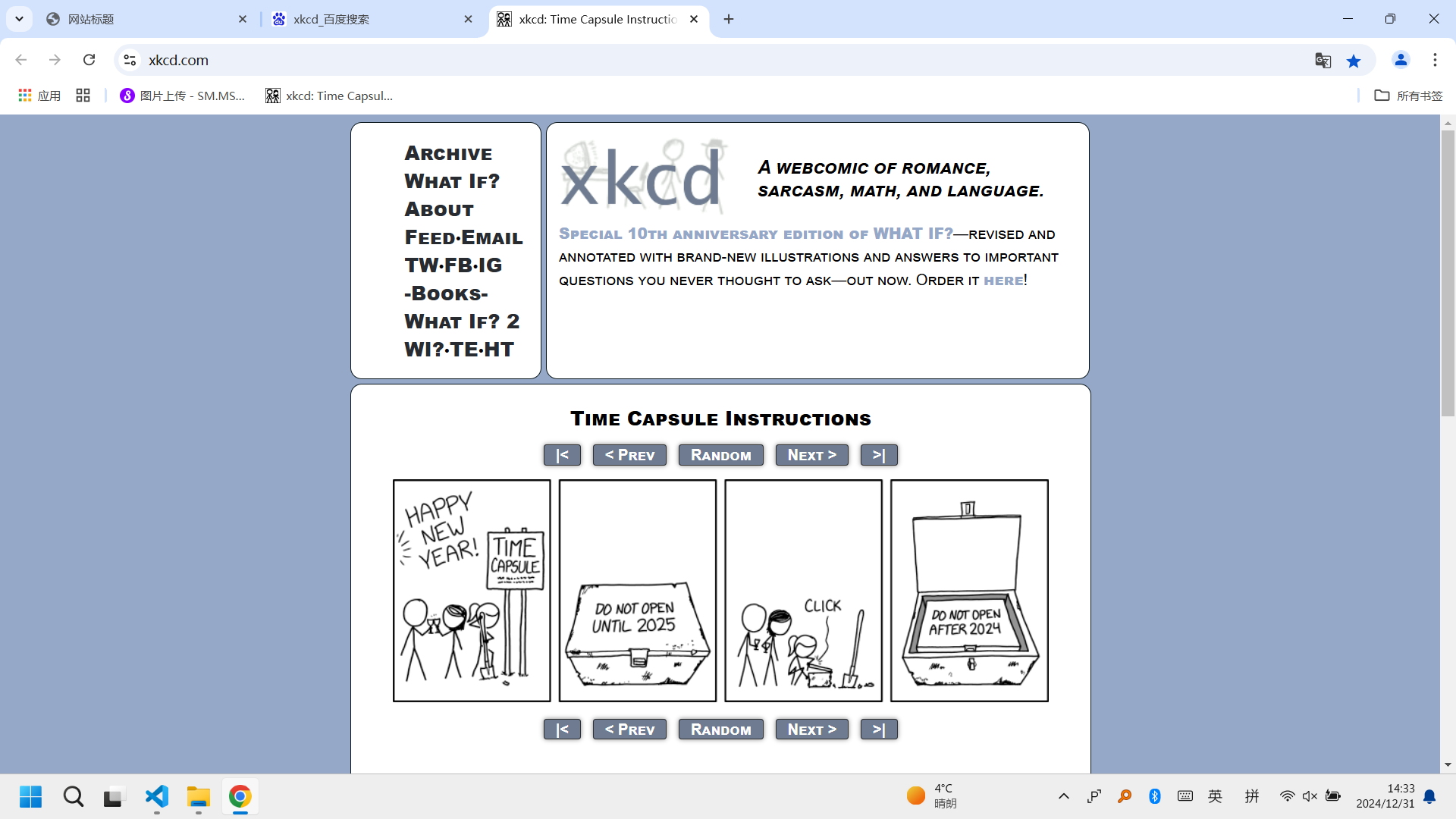
https://xkcd.com/ 的首页默认是最新的一张漫画,如果此时点击next,网站url则会变成https://xkcd.com/# ,第一页的url是https://xkcd.com/1/ ,如果此时再点击prev,网站url则会变为https://xkcd.com/1/# 。而且url中的数字是连续变化的,中间没有空值。
使用F12进入开发者模式(Google,edge,firefox),在elements页面找到图片的url,和下一页的url。
代码
1 | import requests, os, time, re |
关于代码的一些说明
原书中是从最新一张漫画的页面开始,一直获取上一页的url,但是我们看漫画的顺序都是从前往后看,所以我将顺序更改为了从第一张图片开始。
原书中是用图片的comic_url来命名图片,这使得图片名称过长,我更改为了使用url的数字序号来命名。
 微信支付
微信支付 支付宝
支付宝
